


Operation Chaos

...Heaven is not as narrowly literal-minded as hell.
Whatever else one might say about Anderson’s theological musings, this observation is profoundly true.
The Mechanism of Morality
Suppose we want to teach a computer to play the game of Tic-Tac-Toe. Tic-Tac-Toe is a game between two players that takes place on a 3x3 grid. Each player has a marker, typically X and O, and the object is for a player to get three markers in a row: horizontally, vertically, or diagonally.
One possible game might go like this:
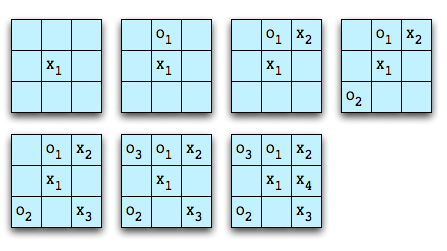
Player X wins on the fourth move. Player O lost the game on the first move since every subsequent move was an attempt to block a winning play by X. X set an inescapable trap on the third move by creating two simultaneous winning positions.
In general, game play starts with an initial state, moves through intermediate states, and ends at a goal state. For a computer to play a game, it has to be able to represent the game states and determine which of those states advance it toward a goal state that results in a win for the machine.
Tic-Tac-Toe has a game space that is easily analyzed by “brute force.” For example, beginning with an empty board, there are three moves of interest for the first player:
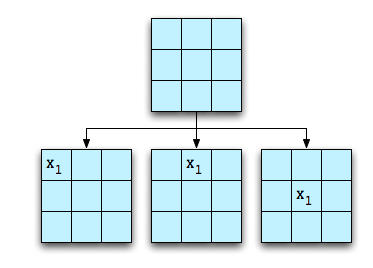
The other possible starting moves can be modeled by rotation of the board. The computer can then expand the game space by making all of the possible moves for player O. Only a portion of this will be shown: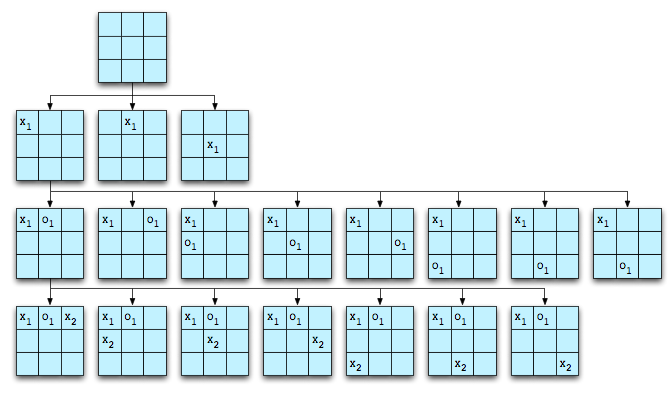
The game space can be expanded until all goal states (X wins, O wins, or draw game) are reached. Including the initial empty board, there are 4,163 possible board configurations.
Assuming we want X to play a perfect game, we can “prune” the tree and remove those states that inevitably lead to a win by O. Then X can use the pruned game state and chose those moves that lead to the greatest probability of a win. Furthermore, if we assume that O, like X, plays a perfect game, we can prune the tree again and remove the states that inevitably lead to a win by X. When we do this, we find that Tic-Tac-Toe always results in a draw when played perfectly.
While a human could conceivably evaluate the entire game space of 4,163 boards, most don’t play this way. Instead, the human player develops a set of “heuristics” to try to determine how close a particular board is to a goal state. Such heuristics might include “if there is a row with two X’s and an empty square, place an X in the empty square for the win.” “If there is a row with two O’s and an empty square, place an X in the empty square for the block.” More skilled players will include, “If there are two intersecting rows where the square at the intersection is empty and there is one X in each row, place an X in the intersecting square to set up a forced win.” Similarly is the heuristic that would block a forced win by O. This is not a complete set of heuristics for Tic-Tac-Toe. For example, what should X’s opening move be?
Games like Chess, Checkers, and Go have much larger game spaces than Tic-Tac-Toe. So large, in fact, that it’s difficult, if not impossible, to generate the entire game tree. Just as the human needs heuristics for evaluating board positions to play Tic-Tac-Toe, the computer requires heuristics for Chess, Checkers, and Go. Humans expand a great deal of effort developing board evaluation strategies for these games in order to teach the computer how to play well.
In any case, game play of this type is the same for all of these games. The player, whether human or computer, starts with an initial state, generates intermediate states according to the rules of the game, evaluates those states, and selects those that lead to a predetermined goal.
What does this have to do with morality? Simply this. If the computer were self aware and was able to describe what it was doing, it might say, “I’m here, I ought to be there, here are the possible paths I could take, and these paths are better (or worse) than those paths.” But “better” is simply English shorthand for “more good” and “worse” is “less good.” For a computer, “good” and “evil” are expressions of the value of states in goal-directed searches.
I contend that it is no different for humans. “Good” and “evil” are the words we use to describe the relationship of things to “oughts,” where “oughts” are goals in the “game” of life. Just as the computer creates possible board configurations in its memory in order to advance toward a goal, the human creates “life states” in its imagination.
If the human and the computer have the same “moral mechanism” -- searches through a state space toward a goal -- then why aren’t computers as smart as we are? Part of the reason is because computers have fixed goals. While the algorithm for playing Tic-Tac-Toe is exactly the same for playing Chess, the heuristics are different and so game playing programs are specialized. We have not yet learned how to create universal game-playing software. As Philip Jackson wrote in “Introduction to Artificial Intelligence”:However, an important point should be noted: All these skillful programs are highly specific to their particular problems. At the moment, there are no general problem solvers, general game players, etc., which can solve really difficult problems ... or play really difficult games ... with a skill approaching human intelligence.
In Programs with Common Sense, John McCarthy gave five requirements for a system capable of exhibiting human order intelligence:
- All behaviors must be representable in the system. Therefore, the system should either be able to construct arbitrary automata or to program in some general-purpose programming language.
- Interesting changes in behavior must be expressible in a simple way.
- All aspects of behavior except the most routine should be improvable. In particular, the improving mechanism should be improvable.
- The machine must have or evolve concepts of partial success because on difficult problems decisive successes or failures come too infrequently.
- The system must be able to create subroutines which can be included in procedures in units...
That this seems to be a correct description of our mental machinery will be explored in future posts by showing how this models how we actually behave. As a teaser, this explains why the search for a universal morality will fail. No matter what set of “oughts” (goal states) are presented to us, our mental machinery automatically tries to improve it. But for something to be improvable, we have to deem it as being “not good,” i.e. away from a “better” goal state.